NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.Natural Language Processing with Python provides a practical introduction to programming for language processing. Written by the creators of NLTK, it guides the reader through the fundamentals of writing Python programs, working with corpora, categorizing text, analyzing linguistic structure, and more.
Lets start with steps to install NLTK and other utilities.
Steps:





Lets start with steps to install NLTK and other utilities.
Steps:
- Install Python: http://www.python.org/download/releases/2.7.3/
- Install Numpy (optional):http://sourceforge.net/projects/numpy/files/NumPy/1.6.2/numpy-1.6.2-win32-superpack-python2.7.exe
- Install NLTK: http://pypi.python.org/pypi/nltk
- Install PyYAML: http://pyyaml.org/wiki/PyYAML
Now if you type the command import nltk at IDLE shell you'll get the nltk module loaded and cursor will come to next line.
Power of NLTK:
1. Tokenizer: This returns you list of tokens present in a sentence you provide as parameter to tokenizer.
2. Part of Speech tagger: This tags the tokens within sentence with appropriate tags like NP, VP, JJ, etc.
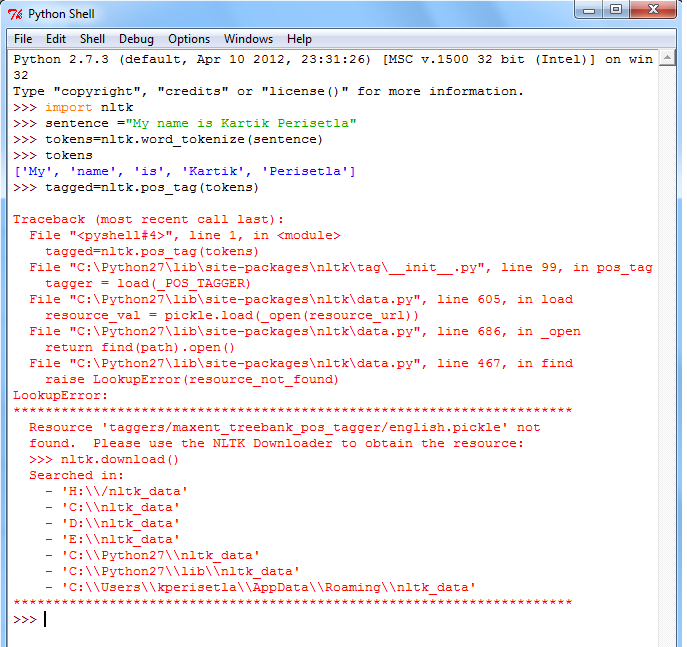
It is possible that you get such error:
You can resolve this with command nltk.download(). This will bring the NLTK downloader:
Select the "book" entry and hit download button. This will start downloading required packages associated with book. In this step we are actually downloading corporus for NLTK.
Once you download the corporus, rerun the same command and you will see sentence being tagged with Nouns, Verbs, Adjective,etc. :
3. Parse Tree using Context Free Grammar(CFG)
Now lets see the power of recursive descent parser in recognizing a sentence apropos to a context free grammar. Consider we have a context free grammar:
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
Sample sentence that can be produced by this grammar is :
Mary saw Bob
Let see how it works:
- We start with specifying the grammar
- We split the sentence in tokens by " "( blank space)
- We create instance of recursive descent parser using this grammar
- We create a tree by calling parse method of the parser
- As a result we get the parse tree for the sentence
I hope this post throws some light on natural language processing capabilities of python.